http发展史
HTTP
HTTP 协议是个无状态协议,不会保存状态。
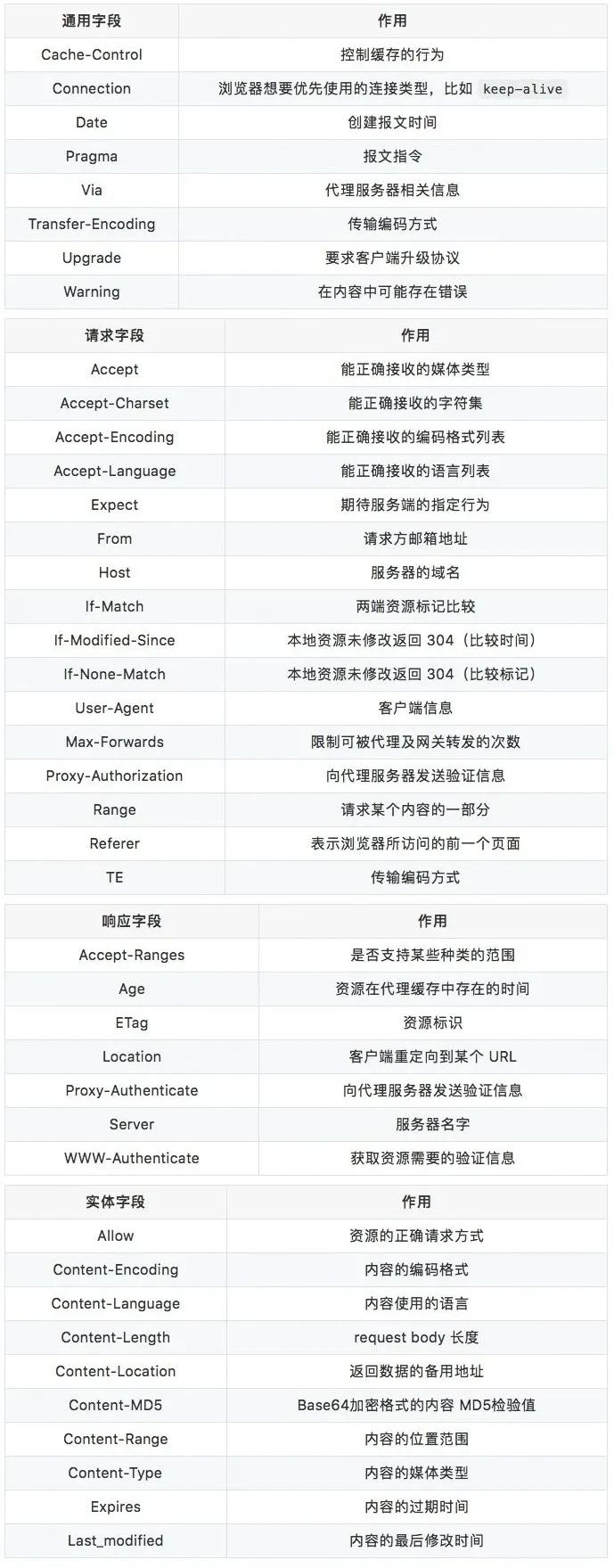
HTTP 首部
HTTPS
HTTPS 还是通过了 HTTP 来传输信息,但是信息通过 TLS、SSl 协议进行了加密。
HTTP/1.0
1.除了GET命令,还引入了POST命令和HEAD
2.包括状态码(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等。
HTTP/1.1
持久连接
管道机制1.1 版还引入了管道机制(pipelining),即在同一个TCP连接里面,客户端可以同时发送多个请求。这样就进一步改进了HTTP协议的效率。
Content-Length 字段,回应的长度
1.1版还新增了许多动词方法:
PUT、PATCH、HEAD、OPTIONS、DELETE。另外,客户端请求的头信息新增了
Host字段,用来指定服务器的域名。
虽然1.1版允许复用TCP连接,但是同一个TCP连接里面,所有的数据通信是按次序进行的。服务器只有处理完一个回应,才会进行下一个回应。要是前面的回应特别慢,后面就会有许多请求排队等着。这称为“队头堵塞”(Head-of-line blocking)。
为了避免这个问题,只有两种方法:一是减少请求数,二是同时多开持久连接。这导致了很多的网页优化技巧,比如合并脚本和样式表、将图片嵌入CSS代码、域名分片(domain sharding)等等。如果HTTP协议设计得更好一些,这些额外的工作是可以避免的。
HTTP 2.0
HTTP 2.0 相比于 HTTP 1.X,可以说是大幅度提高了 web 的性能。
在 HTTP 1.X 中,为了性能考虑,我们会引入雪碧图、将小图内联、使用多个域名等等的方式。这一切都是因为浏览器限制了同一个域名下的请求数量,当页面中需要请求很多资源的时候,队头阻塞(Head of line blocking)会导致在达到最大请求数量时,剩余的资源需要等待其他资源请求完成后才能发起请求。
二进制传输
HTTP 2.0 中所有加强性能的核心点在于此。在之前的 HTTP 版本中,我们是通过文本的方式传输数据。在 HTTP 2.0 中引入了新的编码机制,所有传输的数据都会被分割,并采用二进制格式编码。
多路复用
在 HTTP 2.0 中,有两个非常重要的概念,分别是帧(frame)和流(stream)。
帧代表着最小的数据单位,每个帧会标识出该帧属于哪个流,流也就是多个帧组成的数据流。
多路复用,就是在一个 TCP 连接中可以存在多条流。换句话说,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求。通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能。
Header 压缩
在 HTTP 1.X 中,我们使用文本的形式传输 header,在 header 携带 cookie 的情况下,可能每次都需要重复传输几百到几千的字节。
在 HTTP 2.0 中,使用了 HPACK 压缩格式对传输的 header 进行编码,减少了 header 的大小。并在两端维护了索引表,用于记录出现过的 header ,后面在传输过程中就可以传输已经记录过的 header 的键名,对端收到数据后就可以通过键名找到对应的值。
服务端 Push
在 HTTP 2.0 中,服务端可以在客户端某个请求后,主动推送其他资源。
可以想象以下情况,某些资源客户端是一定会请求的,这时就可以采取服务端 push 的技术,提前给客户端推送必要的资源,这样就可以相对减少一点延迟时间。当然在浏览器兼容的情况下你也可以使用 prefetch 。
QUIC
这是一个谷歌出品的基于 UDP 实现的同为传输层的协议,目标很远大,希望替代 TCP 协议。
该协议支持多路复用,虽然 HTTP 2.0 也支持多路复用,但是下层仍是 TCP,因为 TCP 的重传机制,只要一个包丢失就得判断丢失包并且重传,导致发生队头阻塞的问题,但是 UDP 没有这个机制
实现了自己的加密协议,通过类似 TCP 的 TFO 机制可以实现 0-RTT,当然 TLS 1.3 已经实现了 0-RTT 了
支持重传和纠错机制(向前恢复),在只丢失一个包的情况下不需要重传,使用纠错机制恢复丢失的包
- 纠错机制:通过异或的方式,算出发出去的数据的异或值并单独发出一个包,服务端在发现有一个包丢失的情况下,通过其他数据包和异或值包算出丢失包
- 在丢失两个包或以上的情况就使用重传机制,因为算不出来了


