面试笔记
js位运算
有符号右移>>1 为除2向下取整
无符号右移>>>0 会把符号位设为0 即为正数
diff算法
不建议用index作为key用于v-for 可能会造成所有子节点重新渲染
https://mp.weixin.qq.com/s/S4S0wiRIiWO2PxGweIpCrA
实现es6的flat以及扁平化
|
| 方法/问题 | 实现难度 | 编码思路 |
|---|---|---|
| 递归实现 | 易 | 递归实现,返回新数组 |
reduce实现 |
中 | reduce进行累加操作 |
| 扩展运算符实现 | 中 | 筛选出数组项进行连接 |
split和toString |
易 | 转成字符串再转数组 |
flat方法 |
易 | 特定功能方法直接操作 |
正则和JSON方法 |
中 | JSON方法转成字符串转回过程中正则处理 |
for in 中的index为字符串
|
遍历对象
| 遍历方式 | 是否遍历原型链属性 | 是否遍历非枚举类型属性 | 是否遍历Symbol属性 |
|---|---|---|---|
| for…in | √ | × | × |
| Object.keys() | × | × | × |
| Reflect.ownKeys() | × | √ | √ |
| Object.getOwnPropertyNames() | × | √ | × |
| Object.getOwnPropertySymbols() | × | √ | 只遍历 |
实现深拷贝
使用lodash.cloneDeep();
Json.parse和Json.stringfy,弊端:
- Date 对象变为字符串
- RegExp、Error 对象变为空对象 {}
- 函数、undefined、Symbol 属性丢失
- NaN、Infinity、-Infinity 变为 null
- enumerable 为 false 的属性丢失
- 循环引用的对象不能正确拷贝
```js
//weekMap防止循环引用
function deepClone(obj, hash = new WeakMap()) {if(hash.has(obj)) return obj; let res=null; if(typeof obj!=='object'||obj===null) return obj; const reference=[Date,RegExp,Error,Set,Map]; if(reference.includes(obj.constructor)) return new obj.constructor(obj); else if(Array.isArray(obj)){ res=[]; obj.forEach((value,index)=>{ res[index]=deepClone(value,hash); }) }else{ res={}; for(let key of Reflect.ownKeys(obj)){ res[key]=deepClone(obj[key],hash); } } hash.set(obj,res); return res;}
### 扁平数据结构转Tree
```js
//1.递归 O(n^2)
let res=[];
const genChildren=(pid,result)=>{
for(let item of data){
if(item.pid===pid){
const newItem={...item,children:[]};
result.push(newItem);
genChildren(item.id,newItem.children);
}
}
}
genChildren(0,res);
//2.借助map O(n)
const arrToTree=(arr){
let res=[];
let map={};
for(let item of arr){
let id=item.id;
let pid=item.pid;
if(!map[id]){
map[id]={...item,children:[]};
}
let treeItem={
...item,
children:map[id].children
};
if(pid===0) res.push(treeItem);
else{
if(!map[pid]){
map[pid]={children:[]};
}
map[pid].children.push(treeItem);
}
}
return res;
}
map(parseInt)问题
===parseInt(“1”,0,arr)、parseInt(“2”,1,arr)、parseInt(“3”,2,arr)。
1 NAN NAN
0默认为10进制
parseInt (string , radix)
JS手写实现instanceof (原型链)
|
event事件
通过 element.style.width 这个方法,获取到的是在html元素中内联的宽度。
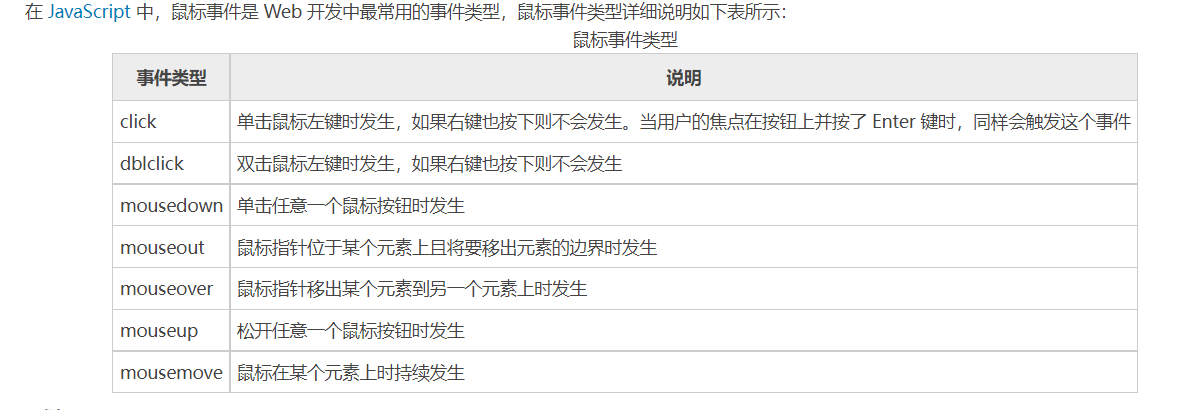
mouseover ,mouseout ,mouseenter,mouseleave,其中mouseover和mouseenter为移入事件,mouseout和mouseleave为移出事件,其中 mouseover和mouseout会受到冒泡到父元素,也受到子元素的影响,其他两个enter和leave为单独
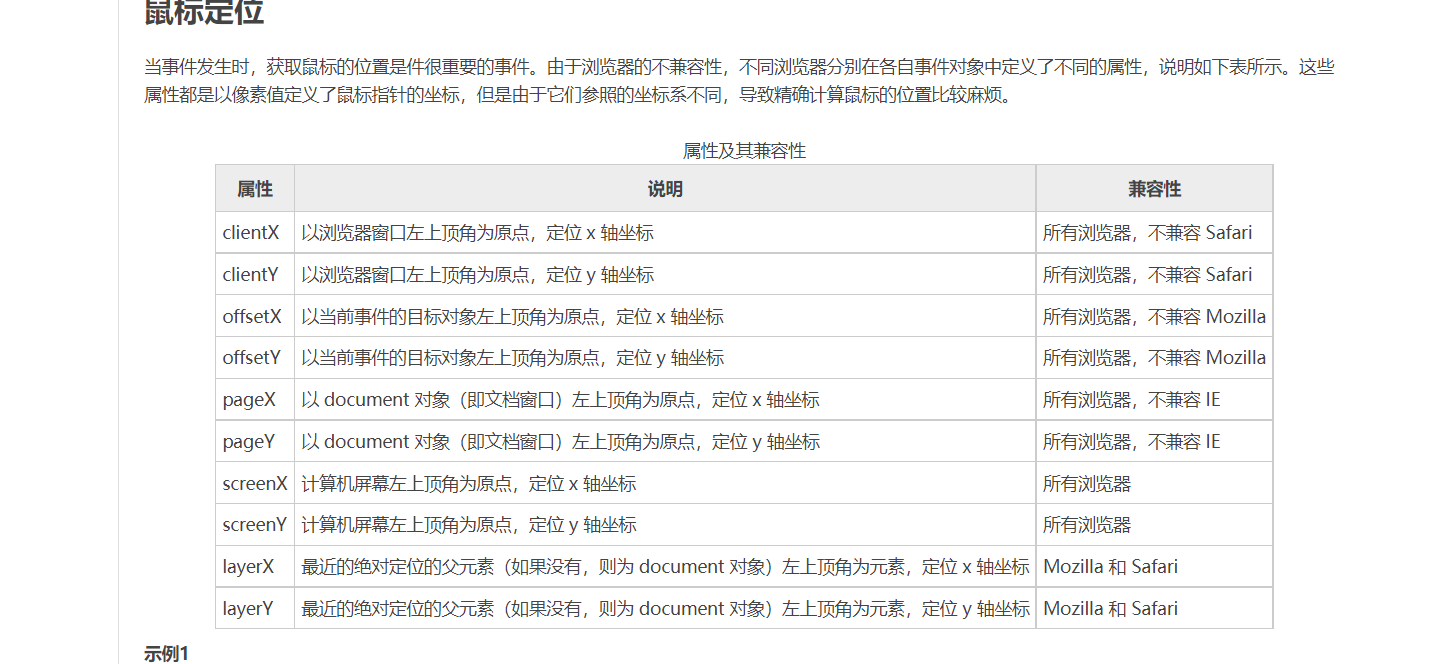
其实绝对定位absolute的参照对象是“离它最近的已定位的祖先元素”,这句话里有两个关键,一个是“离它最近的祖先元素”,意思是那个参照元素不一定是父元素,也可以是它的爷爷、爷爷的爷爷等等,如果它的祖先里同时有2个及以上的定位元素,就参照离它最近的一个元素定位还有一个是“已定位”,这个定位也不一定非要是相对定位,也可以是绝对定位
回流和重绘
当render tree中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建。这就称为回流(reflow),当render tree中的一些元素需要更新属性,而这些属性只是影响元素的外观,风格,而不会影响布局的,比如background-color。则就叫称为重绘。
回流必将引起重绘,而重绘不一定会引起回流。
浏览器会维护1个队列,把所有会引起回流、重绘的操作放入这个队列,等队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会flush队列,进行一个批处理。这样就会让多次的回流、重绘变成一次回流重绘。
虽然有了浏览器的优化,但有时候我们写的一些代码可能会强制浏览器提前flush队列,这样浏览器的优化可能就起不到作用了。当你请求向浏览器请求一些 style信息的时候,就会让浏览器flush队列,比如:
\1. offsetTop, offsetLeft, offsetWidth, offsetHeight
\2. scrollTop/Left/Width/Height
\3. clientTop/Left/Width/Height
\4. width,height
\5. 请求了getComputedStyle(), 或者 IE的 currentStyle
当你请求上面的一些属性的时候,浏览器为了给你最精确的值,需要flush队列,因为队列中可能会有影响到这些值的操作。即使你获取元素的布局和样式信息跟最近发生或改变的布局信息无关,浏览器都会强行刷新渲染队列。
如何优化:
1.批量修改DOM或者样式
- 避免触发同步ui渲染,即强制刷新渲染队列
- 对于复杂的动画效果,使用绝对位置使其脱离文档流
- 使用css3硬件加速
数组的默认排序
数组的默认排序将数组的元素按照字符串的unicode进行排序,因此多位数会出错
+加数字字符变Number类型
+‘11’ ===11
vue2 watch和 vue3 watchEffect区别 纯函数 副作用
纯函数和副作用:
简单来说,纯函数要满足以下条件
(1)它应始终返回相同的值。不管调用该函数多少次,相同的输入都要有相同的输出
(2)它不应修改程序的状态或引起副作用
函数中的副作用(side effect)就是如果有一个函数在输入和输出之外还做了其他的事情,那么这个函数额外做的事情就被称为副作用。而在vue3中专门用了watcheffect来处理副作用
watcheffect,副作用就是它的第一个参数,第一个函数有一个参数叫onInvalidate,用于清楚effect产生的副作用
onInvalidate ,只作用于异步函数,并且只有在如下两种情况下才会被调用:
-
effect函数被重新调用时 - 当监听器被注销时(如组件被卸载了)
watcheffect本身返回一个停止函数,可以停止watcheffect
watcheffect的第二个参数是options,设置副作用发生的时间、debugger等
和vue2的watch相比,
- watcheffect无须传入手动传入依赖
- 每次初始化会自动执行一次effect函数收集依赖
- 无法获取原值,只能获取变化后的值
跨域问题
什么是跨域:
浏览器由于同源策略(相同协议,相同host,相同端口)的限制,出于安全,阻止一个域的javascript和另一个域的内容进行交互!
解决方法:
设置document.domain节解决非同源网页的cookie问题
kua文档通信api:window.postMessage()
页面和其打开的新窗口的数据传递
多窗口之间消息传递
页面与嵌套的iframe消息传递
上面三个场景的跨域数据传递
jsonp简单适用,但只支持get请求
原理:<script>标签的src属性并不被同源策略所约束
实现:
|
- CORS W3C 标准,属于跨源 AJAX 请求的根本解决方法 (前端无需做任何设置,浏览器会在header中加入origin请求头字段)
1、普通跨域请求:只需服务器端设置Access-Control-Allow-Origin
2、带cookie跨域请求:前后端都需要进行设置
必须在 AJAX 请求中打开withCredentials,需要注意的是,如果要发送 Cookie,Access-Control-Allow-Origin就不能设为星号,必须指定明确的、与请求网页一致的域名。同时,Cookie 依然遵循同源政策,只有用服务器域名设置的 Cookie 才会上传,其他域名的 Cookie 并不会上传,且(跨域)原网页代码中的document.cookie也无法读取服务器域名下的 Cookie。
非简单请求(预检请求)
|
webpack本地代理 devServer
Nginx反向代理
websocket 双向链接 不存在跨域
indexedDB:
浏览器的数据库 不是关系型数据库 有点类似Nosql,不适用sql语言 键值(Key-Value)存储数据库
vuex
state 存储状态 mutation 同步修改状态 actions 异步修改状态(会用到mutation)
!-1
不等于true 赋值为0在if中则为假,0.0也是假,其他数值认为是真,不区分带小数点和整数,正数和负数
客户端渲染和ssr
客户端渲染: seo性能差,首屏加载慢
步骤:
node服务,把相关的js加载进来
接受请求。分析出请求的页面,找到对应的vue实
vue实例转化为html
返回html给浏览器
nuxt: ssr vue 框架
所有在全局作用域中声明的变量、函数都会变成window对象的属性和方法。(浏览器是,node不是)
css sprite css 图片精灵
它允许你将一个页面涉及到的所有零星图片都包含到一张大图中去,这样一来,当访问该页面时,载入的图片就不会像以前那样一幅一幅地慢慢显示出来了
domcontentload load
- DOMContentLoaded
当初始的 HTML 文档被完全加载和解析完成之后,DOMContentLoaded 事件被触发,而无需等待样式表、图像和子框架的完成加载。
js的解析会阻塞html解析, js 执行完之前会加入css已经加载完,会先渲染一遍
- load
load 仅用于检测一个完全加载的页面,页面的html、css、js、图片等资源都已经加载完之后才会触发 load 事件。
slot 插槽
父组件中使用子组件时,插入子组件内部时,也是子组件对父组件通信的方式
|
沙箱模式
限制动态js的执行环境,主要是为了安全,防止XSS 方式:
1. new Function (只可以访问函数内和全局作用域)+eval+with +proxy(只可以访问with的作用域通过proxy代理with中对象的has)
1. iframe嵌套
1. nodeJS的VM Module
浏览器的渲染进程
- GUI渲染进程
渲染浏览器界面,负责解析html和css,构建DOM CSSDOM RenderDOM
负责重绘、回流
- JS引擎线程
负责解析js,执行js代码
注意:JS引擎线程和GUI线程互斥,则当解析html或css时,遇到执行js,会挂起解析html或css,所以,当js执行过长,会堵塞页面渲染
- 事件触发引擎
控制事件循环,当js引擎执行代码时遇到setTimeOut(或者可是来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应的任务添加到事件触发线程中,当对应事件符合触发条件时,该线程会把时间添加到js任务队列的队尾,等待js引擎处理。
- 定时器触发线程
setTimeOut、setInterval所在线程
- 异步http请求线程
网络请求
不要在构造函数中定义方法
原因:
- 每次new 都会产生一个函数地址,造成性能低下
- 产生大量闭包,有可能造成内存泄漏
建议在prototype中定义方法,供所有实例类使用
事件捕获 事件冒泡
先是事件捕获(从根节点到目标节点) 再到事件冒泡 (从目标节点到根节点)
加入冒泡机制是因为存在这个现象 子元素存在于父级元素,你点击子元素也是相当于点击了父元素,然后冒泡机制可用于事件委托,优化性能,比如长列表绑定事件
每个li上绑定事件,li触发事件,如果1kw条数据,这种做法肯定是不科学的。所以,优化性能的时候,将事件绑定在ul上,加入冒泡机制,代码量变少、性能又好。
浏览器缓存 强缓存 协商缓存 启发式缓存
缓存的位置 :内存缓存 硬盘缓存 (service worker(以让开发者自己控制管理缓存的内容以及版本))
缓存的分类
强缓存
通过 expires Cache-Control字段判断是否命中强缓存
- expires 该字段表示一个绝对时间的 GMT 格式字符串,代表着这个资源的失效时间。在此时间之前,则缓存未失效。
- Cache-Control 当中max-age为资源有限时间 ,其中还有其他属性
- no-cache:需要进行协商缓存,发送请求到服务器表示确认是否使用缓存
- no-store:禁止使用缓存,每一次都要重新请求
- public:可以被所有用户缓存,包括终端用户和 CDN 等中间代理服务器
- private:只能被终端用户缓存。
- must-revalidate: 当强缓存未能命中是,强制协商缓存成功后才可以使用缓存(有可能协商缓存请求失败等网络请求失败,会使用缓存)
- expires Cache-Control可同时使用,但Cache-Control优先级更高
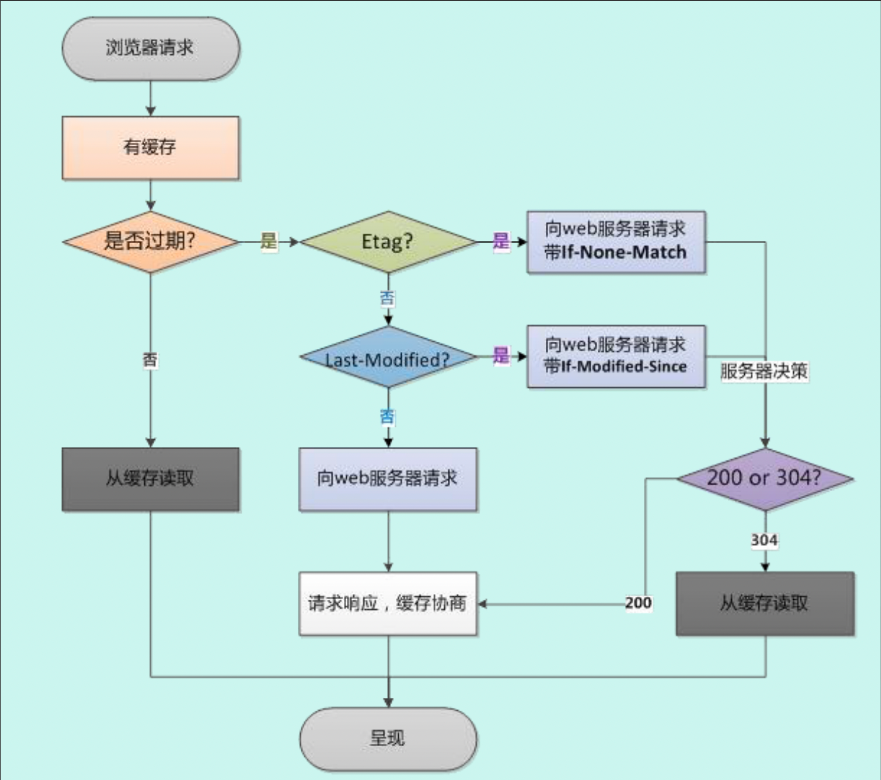
协商缓存
强缓存未命中 则会通过协商缓存,向服务器发送(带If-Modify-Since If-None-Match)请求判断L是否命中,304为未修改 继续使用缓存,200则需重新向服务器请求
If-Modify-Since(Last-Modify)
在第一次请求是,返回头有Last-Modify,代表资源最后的修改时间,当再次请求时If-Modify-Since会携带这个值,让服务器判断是否过期
If-None-Match(ETag)
因为Last-Modify只是资源修改时间,有可能内容并未发生变化(增加注释等),因此新增一个ETag,它是根据文件内容生成的一个hash值,保证资源唯一性
ETag比Last——Modify优先验证
启发式缓存
如果没有Cache-control,expires,即没有缓存时,但要是有Last-Modified字段,可以启动启发式缓存,即为Date 响应头的时间减去 Last-Modified 的时间
ctrl+F5 强制刷新页面时,强缓存和协商缓存都会失效,但仅是F5刷新仍可进行协商缓存但不能强缓存
VUE v-if和v-for
vue2 中v-for比v-if优先级更高
vue3中v-if优先级更高
CSS 选择器优先级的计算规则
!import>行内>id>class>标签
每一段 CSS 语句的选择器都可以对应一个具体的数值,数值越大优先级越高,其中的 CSS 语句将被优先渲染。具体规则为:
- 出现一个 0 级选择器,优先级数值
+0; - 出现一个 1 级选择器,优先级数值
+1; - 出现一个 2 级选择器,优先级数值
+10; - 出现一个 3 级选择器,优先级数值
+100。
vue的优点
mvvm 数据驱动视图 Model-View-ViewModel
- 轻量级框架:只关注视图层,是一个构建数据的视图集合,大小只有几十kb;
- 上手比较容易:很多语法糖;
- 双向数据绑定:保留了angular的特点,在数据操作方面更为简单;
- 组件化:保留了react的优点,实现了html的封装和重用,在构建单页面应用方面有着独特的优势;
- 视图,数据,结构分离:使数据的更改更为简单,不需要进行逻辑代码的修改,只需要操作数据就能完成相关操作;
- 虚拟DOM:dom操作是非常耗费性能的,不再使用原生的dom操作节点,极大解放dom操作,但具体操作的还是dom不过是换了另一种方式;
- 运行速度更快:相比较与react而言,同样是操作虚拟dom,就性能而言,vue存在很大的优势,一个状态改变,react需要patch的节点往往会更多。
- diff算法不同。
react主要使用diff队列保存需要更新哪些DOM,得到patch树,再统一操作批量更新DOM。Vue使用双向指针,边对比,边更新DOM - 数据流向的不同。
react从诞生开始就推崇单向数据流,而Vue是双向数据流
函数柯里化
tip:函数的length就是参数的长度
tip:用到了闭包
|
前端工程化
为了让前端开发能够成为一个工程化的体系,更加严谨、便捷、安全,更高效率,降低成本。
- 模块化 将一个大文件拆分成相互依赖的小文件,在进行统一的拼接和加载
- 组件化 在设计层面上对UI进行拆分
- 规范化 TS,语义化标签,W3C规范,等等使得更有语义,可维护性更高
- 自动化 一些自动化检查命名规范、格式化代码等等
软件架构
事件驱动架构
事件(event)是状态发生变化时,软件发出的通知。
事件驱动架构(event-driven architecture)就是通过事件进行通信的软件架构。
设计模式
三大类:
创建型模式(Creational Pattern)
对类的实例化过程进行了抽象,能够将软件模块中对象的创建和对象的使用分离。
(5种)工厂模式、抽象工厂模式、单例模式、建造者模式、原型模式
结构型模式(Structural Pattern)
关注于对象的组成以及对象之间的依赖关系,描述如何将类或者对象结合在一起形成更大的结构,就像搭积木,可以通过简单积木的组合形成复杂的、功能更为强大的结构。
(7种)适配器模式、装饰者模式、代理模式、外观模式、桥接模式、组合模式、享元模式
行为型模式(Behavioral Pattern)
关注于对象的行为问题,是对在不同的对象之间划分责任和算法的抽象化;不仅仅关注类和对象的结构,而且重点关注它们之间的相互作用。
(11种)策略模式、模板方法模式、观察者模式、迭代器模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式
前端新技术
微前端
多个子应用合成到一块,不分框架,框架 阿里的qiankun 主要的问题:子应用之间的信息交流等
SSR服务端渲染
使首屏加载更快,SEO优化更好等 vue有nuxt
Low-Code 低代码
Webasseme
WebAssembly提供了一种以近乎本机的速度在网络上运行,与 javaScript 赋予了Web极大的性能提升,使得再js上可以运行c,c++这些高级语言
几张图让你看懂WebAssembly - 简书 (jianshu.com)
Serverless
Serverless,又叫无服务器。Serverless 强调的是一种架构思想和服务模型,让开发者无需关心基础设施(服务器等),而是专注到应用程序业务逻辑上。Serverless 也是下一代计算引擎.
让各大服务托管商区运维服务器,开发者专注到应用程序业务逻辑
云函数是serverless的一种具体实现。
设备像素、css像素、设备独立像素、dpr、ppi
- 设备像素 也称为物理像素,即设备能控制显示的最小物理单位,从屏幕在工厂生产出的那天起,它上面设备像素点就固定不变了,单位为
pt - css像素 CSS像素(css pixel, px): 适用于web编程,在 CSS 中以 px 为后缀,是一个长度单位
- 设备独立像素,与设备无关的逻辑像素,代表可以通过程序控制使用的虚拟像素,是一个总体概念,包括了CSS像素
- 设备像素比dpr(device pixel ratio),代表设备独立像素到设备像素的转换关系,当设备像素比为2:1时,使用4(2×2)个设备像素显示1个CSS像素,那么
1px的CSS像素宽度对应2px的物理像素的宽度,1px的CSS像素高度对应2px的物理像素高度 - ppi像素密度,表示每英寸所包含的像素点数目 值越大,图像越清晰 PPI = sqrt(H^2 + V^2) / Inch
一般情况下,1个css像素=1个设备独立像素=1个物理像素。
em rem为相对单位,em相对父节点,rem相对根节点,若根font-size为100px,1rem=100px;
vh vw 为相对高宽度,根据窗口的宽度,分成100等份
进程和线程间的通讯方式
进程通信
几种进程间的通信方式
(1) 管道(pipe):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有血缘关系的进程间使用。进程的血缘关系通常指父子进程关系。
(2)有名管道(named pipe):有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间通信。
(3)信号量(semophore):信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它通常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
(4)消息队列(message queue):消息队列是由消息组成的链表,存放在内核中 并由消息队列标识符标识。消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
(5)信号(signal):信号是一种比较复杂的通信方式,用于通知接收进程某一事件已经发生。
(6)共享内存(shared memory):共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问,共享内存是最快的IPC方式,它是针对其他进程间的通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间的同步和通信。
(7)套接字(socket):套接口也是一种进程间的通信机制,与其他通信机制不同的是它可以用于不同及其间的进程通信。
线程通信
(1)、锁机制
|
(2)、信号量机制:包括无名线程信号量与有名线程信号量
(3)、信号机制:类似于进程间的信号处理。
线程间通信的主要目的是用于线程同步,所以线程没有象进程通信中用于数据交换的通信机制
内存分配 连续与不连续
连续
单一连续分配
- 分配方法:将内存去划分为系统区域用户区,系统区为操作系统使用,剩下的用户区给一个进程或作业使用。
- 特点:操作简单、没有外部碎片,适合单道处理系统。但是会有大量的内部碎片浪费资源,存储效率低。
固定分区分配
- 分配方法:(1)分区大小相等:将内存的用户区分成大小相等的区域,每个进程只能申请一块区域;(2)分区大小不等:将内存的用户区分成大小不等的区域,分配原则是多个较小的区域、适量中等大小区域、少量的最大分区。每个进程根据大小只能申请一块区域。
- 特点:固定分区分配虽然没有外部碎片,但是会造成大量的内部碎片。分区大小相等缺乏灵活性,大的进程可能放不进去;分区大小不等可能会造成大量的内部碎片,利用率极低。
动态分区分配
- 分配方法:不会先划分内存区域,当进程进入内存的时候才会根据进程大小动态的为其建立分区,使分区大小刚好适合进程的需要。
- 特点:在开始是很好的,进程一次按照顺序存入内存,但是运行久了以后随着进程的消亡,会出现很多成段的内存空间,时间越来越长就会导致很多不可利用的外部碎片,降低内存的利用率。这时需要分配算法来解决
分配算法
- 首次适应算法:进程进入内存之后从头开始查找第一个适合自己大小的分区。空间分区就是按照地址递增的顺序排列。算法开销小,回收后放到原位置就好。综合看这个算法性能最好。
- 最佳适应算法:将分区从从小到大排列(容量递增),找到最适合自己的分区,这样会有更大的分区被保留下来,满足别的进程需要。但是算法开销大,每次进程消亡产生新的区域后要重新排序。并且当使用多次后会产生很多外部碎片。
- 最坏适应算法:将分区从从大到小排列(容量递减),进程每次都找最大的区域来使用。可以减少难以利用的外部碎片。但是大分区很快就被用完了,大的进程可能会有饥饿的现象。算法开销也比较大。
- 邻近适应算法:空间分区按照地址递增的顺序进行排列,是由首次适应演变而来,进程每次寻找空间,从上一次查找的地址以后开始查找(不同于首次适应,首次适应每次从开头查找)。算法开销小,大的分区也会很快被用完。
- 注意:以上进程使用空间不会产生内部碎片,当进程大小为60mb的进程找到了一块100mb的空间,他只会使用60mb,剩下的40mb会给别的进程。
非连续
基本分页
- 把主存空间划分为大小相等的块,块相对较小,作为主存的基本单元。每个进程也以块为单位划分,进程执行时,以块为单位申请内存空间
- 进程中的块的各个代码,在内存中对应的物理地址是=页表中物理内存块号+地址结构中页内偏移量
基本分段
- 分段:按照进程自然划分炒年成逻辑空间,例如进程由主程序、两个子程序、栈和数据组成。于是可以把这个进程分成5段,每一段的逻辑地址从0开始编址,并分配一段连续的内存空间。(注意这里段内必须连续,段与段之间可以分散)
- 逻辑地址结构:是由两部分组成第一部分为段号S,看进程是哪一个段,段号的位数决定了进程分了多少段;第二部分为段内偏移量W,段内偏移量决定了这段进程的最大长度。
- 段表:每个进程都以一张逻辑空间与内存空间映射的段表,每个段表对应进程的一段,段表项季度该段在内存中的起始地址和长度。段表由三个部分组成:段号、段长、本段在主存中的起始地址(基址)。
段页式管理方式
- 概念:首先将进程根据逻辑结构划分成若干个逻辑段,每个段都有自己的段号,然后将这些段划分成若干个大小固定的页。这样对内存空间的管理依然和分页式管理相似,将内存分成和页面大小相同的存储块,对内存分配一存储块为单位。
- 逻辑地址结构:逻辑地址结构由段号S(决定每个进程的段数)、页号P(决定每段的页数)、页内偏移量W(页面的大小和内存块的大小)组成。
WebComponents
原生自定义组件的管理与复用
技术点:
Custom elements
|
Shadow DOM
让组件内的各个元素和DOM隔离,自定义组件内部的各种元素对外不可见{model:closed}
HTML templates
它可以让你用原生html、css、js语言来编写组件。
|
Template slot
为影子树中的该元素提供了一个插槽。
|
Git rebase 和Git merge
git merge:merge 是一个合并操作,会将两个分支的修改合并在一起,默认操作的情况下会提交合并中修改的内容,即将差异合并生成一个新的commit;提交历史会相互交织
git rebase 并没有进行合并操作,只是提取了当前分支的修改,将其复制在了目标分支的最新提交后面。提交历史更加干净整洁。
git merge更注重于历史 git rebase更注重于内容,开发过程上面
合并冲突:
git merge会停止merge,需要将冲突解决后重新git add git commit,之后再重新merge
git rebase也会停止rebase,解决冲突后git add后使用git rebase–continue,继续rebase
暂时性死区
暂时性死区的本质就是,只要一进入当前作用域,所要使用的变量就已经存在了,但是不可获取,只有等到声明变量的那一行代码出现,才可以获取和使用该变量。
|
进程和线程 协程 并发并行
进程是操作系统资源调度的基本单位,是应用程序执行的载体,进程是一种抽象的概念,没有具体的统一标准定义
线程是任务的调度执行的基本单位,程序执行流的最小单元
协程,英文Coroutines,是一种基于线程之上,但又比线程更加轻量级的存在,这种由程序员自己写程序来管理的轻量级线程叫做用户空间线程,具有对内核来说不可见的特性。
【区别】:
调度:线程作为调度和分配的基本单位,进程作为拥有资源的基本单位;
并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行;
拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源。
系统开销:在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。但是进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个进程死掉就等于所有的线程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。
一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程
并发:在某个时间段上,几个程序同时在一个cpu上执行,但在任意一个时间点上,只有一个程序在cpu上执行
并行:有多个cpu,两个线程可以同时执行
- 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
- 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
- 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。


